

こんにちは!アイスタイル Advent Calendar 2019の 12日目を担当させていただくkakizakihです。
本記事では今年7月から現在まで携わってきた「新データ基盤構築」について、個人的な振り返りと共に書いていきたいと思います。
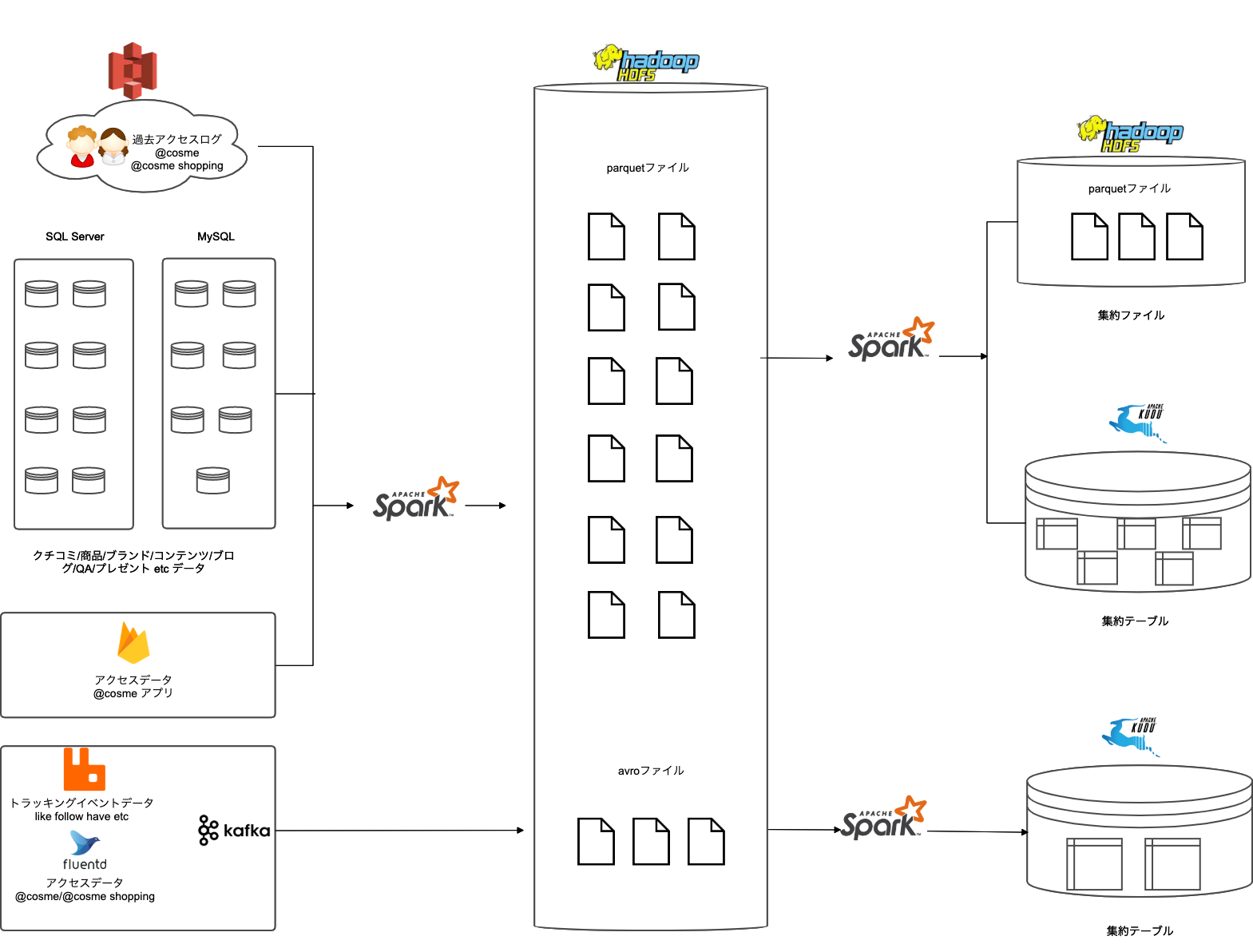
現時点では、下記の図のようなデータ基盤アーキテクチャが完成しております。
新しくデータ基盤を構築するに至った経緯から完成するまでの過程などを、月ごとにエピソードを交えながら振り返っていきたいと思います!
7月 PJ発足
BrandOfficialの新機能リリースに向けた集約処理の開発と新データ基盤を作ろうというPJに参画することになりました。
元々弊社にはこちらの記事でもご紹介している通りBigQueryとHadoopに構築したデータ基盤が存在します。
今回BrandOfficialで新機能をリリースするに当たって、
- BigQueryにあるデータだけだと要件が満たせない
- digdagで定義しているワークフロー処理が複雑になっている
という課題があったため(Brand Official を支える技術)、機械学習で利用している実績があるHDFS上に足りないデータを収集し、こちらも実績があるSparkで集約処理を行うことになりました。
しかし既存のHadoop基盤の構成では
- メモリやディスクが足りない
- 構築手順などもブラックボックス化している
という課題があり、こちらに関しても新しいHadoop環境を構築して社内の新しいデータ基盤として作り直すことになりました。
8月 Hadoop開発環境構築とデータ収集・集約処理開発
主な作業
- Hadoop開発環境構築(CDH5.16.2)
- RDB、アクセスログ、トラッキングイベントからのデータ収集処理の開発とデータ投入
- HDFSにあるデータを元に集約処理の開発と集約データ投入
エピソード
- Hadoop開発環境構築に4回失敗して5回目で成功する
- 集約処理のステップ数が2000行を超える
9月 データ収集・集約処理開発続きとkuduの導入
主な作業
- 引き続きデータ集約処理の開発
- 集約データの出力をparquetファイルからkuduテーブルへ一部変更
エピソード
- 集約結果をparquetファイルへ書き出し、impalaから読み込んでフロントに返すように実装していたが、クエリを返すのに時間がかかったり重複したデータを考慮した実装に限界がくる → スケーラブル且つ高速で、upsertが可能なkuduテーブルへ一部切り替える
- しかし開発環境のメモリが足りずkuduテーブルへデータがupsertできない
- 追い討ちをかけるようにネットワーク障害で開発環境のHadoopが死亡する
10月 Hadoopステージング/本番環境構築とデータ投入とテスト
主な作業
- Hadoopステージング環境構築(CDH6.3.0)
- Hadoop本番環境構築(CDH6.3.0)
- ステージング環境へ収集・集約データの投入
- テスト実施
エピソード
- 本番環境の構築が1日で終わる想定が1週間かかる
- ステージング環境への収集データの投入が数日かかっても終わらなかったものに対して、indexを貼ったりクエリを修正することで数十分、数時間で完了することに成功する
- 取得する必要のある過去のアクセスデータの保存場所が一箇所に固まっていないことが判明して困る
- テストを行うためのデータを作成することに苦戦する
11月 バグ祭りと本番環境へ収集データの投入
主な作業
- バグ修正作業
- 本番環境へ収集データの投入
エピソード
- 想定していたテーブルの仕様の認識違いが大きなバグを生む
例)タグテーブル
想定していた仕様:商品タグには商品が紐付く = ブランドとも紐付くはずだから、商品タグとjoinして集約しよう
実際の仕様:商品タグには商品が紐付く訳ではなく、独自定義なので不必要な商品情報として集約されてしまっていた - kafkaからのストリーミング処理でデータを集約していた部分で、データ量に対して処理が追いつかずデータの取りこぼしが発生する → ストリーミング処理から毎時バッチでの処理へと変更する
- 過去20年のアクセスログのデータ取り込みが想定していた以上に時間がかかり、macPC5台がかりでデータの取り込みを行う
12月 本番環境へ集約データの投入とパフォーマンス検証
主な作業
- 本番環境へ集約データを投入
- パフォーマンス検証
エピソード
- ステージング環境で1時間ほどで終わっていた日時バッチの処理が、本番環境では8時間かかることが判明する
- 本番環境で集約テーブルが十数億行のレコード数となる
- パフォーマンス向上のため、集約データのほとんどをkuduテーブルへ変更する
- 本番環境のメモリ不足でバッチ実行が落ちる
振り返り
半年間、データ基盤の構築から収集・集約を通してアイスタイルにある様々なデータと触れ合って思った感想としては、
- 数々のサービスの持っているデータ、店舗の購買情報、アクセス履歴といった様々なデータがどのような形式でどこに登録されているのかを把握することが難しい
- データが欠損した時やバッチ処理が失敗した時のリカバリー方法を考慮しながらアーキテクチャを設計することが難しい
- データ量の違いから本番環境と開発・ステージング環境で処理時間が大幅に異なってパフォーマンスを考える必要が出てくるなど、本番でしか起きない問題を把握することが困難
といったデータを扱うことの難しさを強く感じました。
一方で、
- どこにどんなデータがあるのかを実際に把握することができた
- そのデータを一箇所に集める基盤構築の知見が得られた
- 様々なデータを集約するノウハウを得ることができた
ことは個人的なスキルとしてとても良かったなと思います。
今回作った新データ基盤はBrandOfficialの新しい機能として利用される以外にも、機械学習やデータ分析などで利用していく予定で、より豊富になったデータによって精度の向上や新しい発見がされていくことと思います。
データ基盤としても、これからも色々な技術を取り入れながら進化させていきますので、ご興味を持たれた方はぜひ一緒に作りましょう!!
