
はじめに
大体@cosmeのサイトの運用・開発・改善その他何でもエンジニアをやっているttと申します。
前回の記事から綺麗に1年ぶりにブログで書きます。
前回の記事はこちら!
@cosmeの裏側! バックエンドAPIをオンプレミス環境からAWS ECS Fargateに移行した話
今年もアドベンドカレンダーのトップを(無理やり)飾らせて頂きます。
この記事はアイスタイル Advent Calendar 2020 1日目の記事です!
そして去年同様、年に一度のコスメ祭りと称しての一大イベント@cosme Beauty Dayが始まります。今年は何と3日間開催ということで、12/1 20:00から開催です!
@cosmeはアイスタイルが運用する日本最大のコスメ・化粧品の口コミ・ランキングサイトです!
丁度開発チームも慌ただしい最中ですが、興味のある方は是非ご覧になっていただけると幸いです。今年はサーバダウン等の障害が起こらぬように…。
概要
弊社ではアットコスメという日本最大のコスメ・化粧品の口コミ・ランキングサイトを運用している会社となっております。
1999年12月にサービス開始とのことなので(Wikipedia参照)、ちょうど本日から21年目となります。
自分でも20年以上歴史のあるサイトと言うのも老舗と言っていいレベルではないかと実感しますね…。
21周年を迎えた今年から、弊社は@cosmeを使用する全ての方に関して、もっと気持ちよく使ってもらうためにパフォーマンスやUI/UXの改善にかなり大きく注力しています。
日常的に使用している方は、最近スマートフォンサイトの商品ページのUIが少し変更されていることを、お気づきになられているのではないでしょうか?
また、アイスタイル開発部署では機械学習等を取り込んだ新しい取り組みやパフォーマンスの可視化のためのアプリケーションパフォーマンスモニタの導入、一部のサービスにおいてクラウド移行などを行っています。
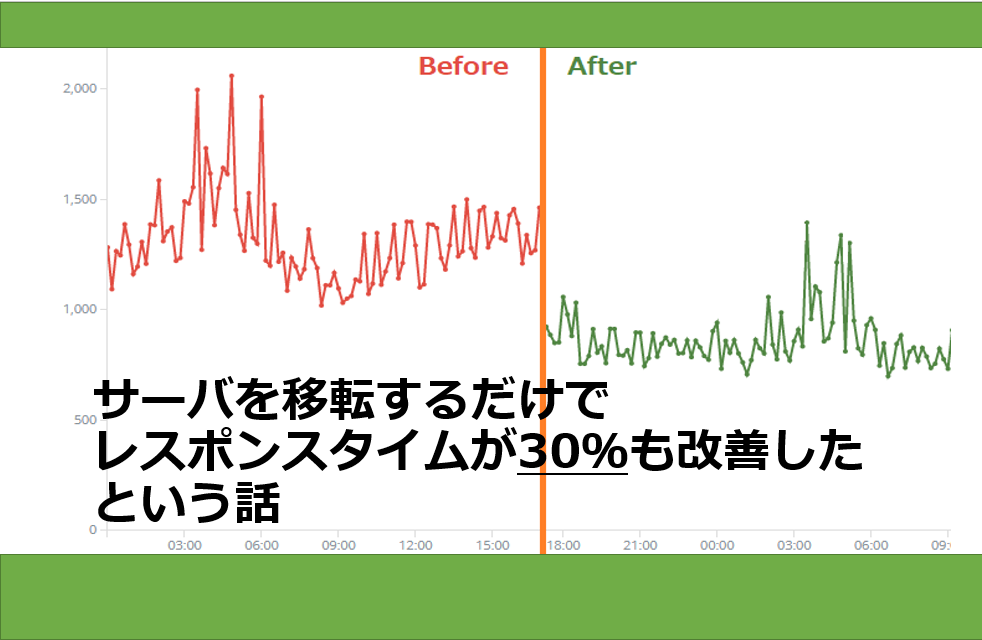
その日々の知見やパフォーマンスに関する実証調査で、「サーバを移転するだけで@cosmeサイト全体のレスポンスタイムが30%も改善した」という話をします。
なおタイトルでは省略していますが、今回の話は厳密には@cosme スマートフォンサイト(以下、@cosme SP版)のサイトに関する話となります。
サーバ移転について
まずサーバ移転とはどういうことか、簡単に説明いたします。
うちには基本的に使用しているデータセンターが2拠点存在致します。
- 東京に存在するデータセンター(以下、東京DC) データベースサーバやキャッシュサーバ
- 福島に存在するデータセンター(以下、福島DC) Webサーバ、LBなど

@cosme SP版のWebサーバは元々福島DCに存在しており、今回ある数値をもとに福島DCから東京DCに移転を行う計画を実行しました。
結果
こちらが実際にNewRelicで測定した、Webサーバで処理している全体レスポンスタイムとなります。実際に見てもらうと一目瞭然です。
福島DCのWebサーバ

東京DCのWebサーバ

ある時間帯を比較してみた表がコチラ。

ということで、ただサーバを移転するだけ30%もレスポンスタイムが改善しました。
これには結果を見た自分もかなり驚きました。サーバを移転するだけでここまで変わる?って思いますよね。
原因について
実は理由については、全然難しいという話ではありません。
一番変動のあった、あるURLの福島DCに存在するサーバのDB/キャッシュサーバの応答速度がこちらです。

そして、東京DCに存在するサーバのDB/キャッシュサーバの応答速度がこちらです。

今回の移転で、DB/キャッシュサーバの平均レスポンスタイムがかなり改善されました。
つまり、原因としてはこうなります。
原因: キャッシュ/DBサーバがWebサーバから物理的に遠かった
まあこういうことですね。
pingを打ってみれば誰でもわかりますが、東京DCから福島DCまで大体10ms(ミリ秒)ほど掛かっておりました。
この10msという数値、Webサーバの1リクエストという考えであればめちゃくちゃ遅いという訳ではないと感じます。
(リアルタイム性を考えるようなサーバであれば、また違いますが)
しかし@cosmeのサイトは長い歴史によりデータ量も半端な数ではなく、データベースもキャッシュサーバに大量のアクセスを行います。
1アクセスで済めば遅延は10msで済みますが、それが100アクセスとなればそれだけで1秒です。1秒となるとWebサーバとしては致命的になり得ます。
今回の例ではサイトへの1アクセスでキャッシュサーバとDBサーバに200アクセスほど飛んでいたため、10ms×200でそれだけで2秒ものオーバヘッドが起きていた、ということとなります。
まさに塵も積もれば山となる・・・ですね。
それが同じデータセンターに移った結果、pingの値は1ms以下となり、オーバヘッドは1/20ほどにまで削減されました。
何故誰も気づくことが出来なかったか
今回の問題は、エンジニアの方なら「物理的に遅いアクセスを大量にしているならそりゃあ遅くなる」と言う感じにお気づきになると思います。
ですが、今まで誰も気づかれず改善に至っておりませんでした。
この原因に関して、3つの要因があると思います。
アプリケーションエンジニアは、本番サーバが何処のデータセンターに存在するか把握できていなかった
まず、アプリケーションエンジニアはほぼ開発環境やステージングを見ており、なおかつ本番のWebサーバが何処のデータセンターにあるということを意識する機会が無かったことが1つ目の原因です。
そのため、このオーバヘッドがあるということを察知できていませんでした。
インフラエンジニアが、どのアプリケーションからDB/キャッシュサーバに大量にアクセスされているか調査出来ていなかった
同じように、インフラエンジニアはどのアプリケーションからDB/キャッシュサーバへアクセスが多いか調査をすることが難しいという問題がありました。
ここに関してはアプリケーション層はアプリケーションエンジニアに任せっきりにしまっているという問題もあります。
本番サーバで、DB/キャッシュサーバにどれだけアクセスされていたか把握出来ていなかった
本番サーバでは、細かいレスポンスタイムやトラフィック数の計測が出来ていませんでした。
なので「キャッシュサーバやDBサーバにアクセスが多い」くらいのざっくりとした知識しかなかったという問題も上げられます。
つまり何が言いたいか言うと
この3つを踏まえまして、つまり何が言いたいか言うと
「推測するな、計測せよ」 です。
(Rob Pike氏のNotes on Programming in Cに書かれている文章が由来だそうです。詳しく知りたい方は調べてね)
今回こちらの問題を発見できた大きな要因として、NewRelic APMの試験導入が非常に大きいです。
これまでも開発やステージングサーバなどでは当然パフォーマンス検証や、サービスの負荷テストなどは行っておりました。
しかし弊社もかなり歴史のあるサービスであるということもあり、本番環境にしか存在しないデータや本番しか動かないような処理はたくさん存在し、誰も知らない隠された仕様のようなものも存在します。(残念なことに)
今回NewRelic APMの試験導入で本番でのパフォーマンスの計測もできるようになり、こういったレスポンスの悪化を察知することができたと思っています。
おわりに
今後とも@cosme運用チームは運用や機能追加だけではなく、@cosme全体のパフォーマンス改善やUI/UXの改善などに注力し、行っていこうと思っています。
今回に関しては、そもそも大量のアクセスがオーバヘッドになっていることが問題なため、このようにならないアーキテクチャなどの移行などもやっていくつもりです。
また弊社では@cosmeサイトだけではなく、ECサイトである@cosme Shoppingや機械学習からBtoBサービスまで、幅広い分野で仲間を募集しています!
