

こんにちは。
アイスタイル DBAのsugatです。
連休はいかがお過ごしですか?
データベースバカな私は良い天気にもかかわらず、
お家でDBの検証な日々です。
寂しくなんか…ないもん…
そんなことより、以前私はこんな記事をQiitaに投稿したのですが、
今回はその続きのお話です。
とあるプロジェクトでMariaDBとSpiderを使おう、という話が挙がったため、
このタイミングでVP(Vertical Partitioning)も導入してみてはどうだろう、と
検証を再開しました。
今回のお題「Vertical Partitioning と Spider ストレージエンジン」
前置きはこれくらいにして、本題に入りましょう。
今回は前回の記事でも紹介した↓の記事を参考にしています。
「OSSのカラム型DBはここまで進化! インサイトテクノロジー・小幡一郎氏」
また、今回初となるVPストレージエンジンについては、MySQLの奥野さんの記事を参考にさせていただきました。
「まるで魔法のようなストレージエンジン??VP for MySQLによる驚愕のテーブル操作テクニック。」
VPストレージエンジンのことがとてもわかりやすく解説されており、
読んだだけですんなりと理解することができます。
これによると、VPストレージエンジンは複数のテーブルを同一PKで結び、
あたかも1つのテーブルであるかのように見せる事ができ、
かつ実体が無いので定義変更も容易に実行できるという…。
使いこなせばNoSQLに匹敵する柔軟なテーブル構造が作れるものなのかな、という印象を受けました。
そして、VPで構成するテーブルの中にSpiderストレージエンジンのテーブルを含めてあげることで、
プロキシ的にSpiderテーブルを使うことでデータの分散を図れるという、DBエンジニアとしては
夢が広がる未来しか見えない!
どんな構成?
今回はこんな構成で検証してみました。
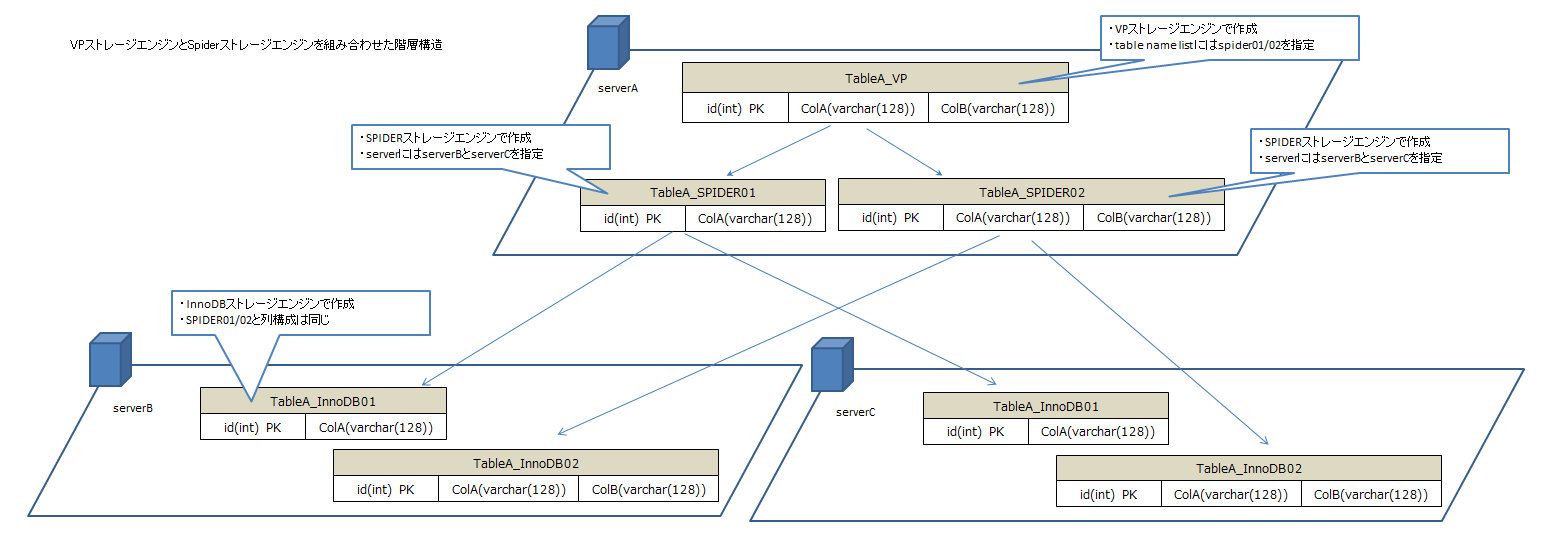
こうすることで、列の追加(≒テーブルの追加)もオンラインで実装しやすく、
実データが入っているInnoDBのテーブルは冗長化が取れているので、
片方が落ちても担保がされるかな、という感じです。
各テーブルのDDLは以下になります。
CREATE TABLE `TableA_VP` (
`id` bigint(20) NOT NULL,
`ColA` varchar(128) DEFAULT NULL,
`ColB` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=VP DEFAULT CHARSET=utf8mb4 COMMENT='table_name_list "TableA_SPIDER01 TableA_SPIDER02"';
CREATE TABLE `TableA_SPIDER01` (
`id` bigint(20) NOT NULL,
`ColA` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=SPIDER DEFAULT CHARSET=utf8mb4 COMMENT='table "TableA_SPIDER01", server "serverB serverC"';
CREATE TABLE `TableA_SPIDER02` (
`id` bigint(20) NOT NULL,
`ColA` varchar(128) DEFAULT NULL,
`ColB` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=SPIDER DEFAULT CHARSET=utf8mb4 COMMENT='table "TableA_SPIDER02", server "serverB serverC"';
実際に入っているレコードのイメージはこちらになります。
+--------+----------------+----------+
| id | ColA | ColB |
+--------+----------------+----------+
| 250001 | hoge | 0 |
| 250002 | hoge | 1 |
| 250003 | hoge | 2 |
| 750001 | fuga | 0 |
| 750002 | fuga | 1 |
| 750003 | fuga | 2 |
| 500001 | aaaa | 0 |
| 500002 | aaaa | 1 |
| 500003 | aaaa | 2 |
| 1 | test | 0 |
| 2 | test | 1 |
| 3 | test | 2 |
+--------+----------------+----------+
ColAとColBでユニークになるようなテーブルです。
ちょっと速度検証してみました
このような形で入っているテーブルに対して、100万件ほどデータを入れ、
ColAごとにGroup Byした結果…
MariaDB [sampledb]> select cola, count(*) from tablea_vp group by cola;
+----------------+----------+
| ColA | count(*) |
+----------------+----------+
| hoge | 250000 |
| fuga | 250000 |
| aaaa | 250000 |
| test | 250000 |
+----------------+----------+
4 rows in set (0.32 sec)
MariaDB [sampledb]> select cola, count(*) from tablea_spider_ha group by cola;
+----------------+----------+
| ColA | count(*) |
+----------------+----------+
| hoge | 250000 |
| fuga | 250000 |
| aaaa | 250000 |
| test | 250000 |
+----------------+----------+
4 rows in set (1.03 sec)
100万件でおおよそ3倍の速さでした。
まとめ
まだまだ検証は必要ですが、用途に寄ってはこういう使い分けも出来ることがわかりました。
オンラインでのカラム追加やサーバーの追加等、やれることはたくさんありそうです。
今後もこの構成については検証してレポートを上げていこうと思います。


